안녕하세요 저번 포스팅에서
테스트링크 젠킨스 연동전에 기본적인 개요 및 전체적인 프로세스 등에 대해서
포스팅하였습니다.
https://ipex.tistory.com/entry/Jenkins-%ED%85%8C%EC%8A%A4%ED%8A%B8%EB%A7%81%ED%81%AC-%EC%A0%A0%ED%82%A8%EC%8A%A4-%EC%97%B0%EB%8F%99-1-%EB%B0%8F-%EC%9B%B9-%EC%9E%90%EB%8F%99%ED%99%94-%EC%8B%9C%EC%8A%A4%ED%85%9C-%EA%B0%9C%EC%9A%94-TestLink-with-Jenkins-Windowsver-and-webAutomation-OverView?category=767972
이번에 작성할 내용은 빌드 작업입니다.
기존 작업 기능 List
1. General 탭
오래된 빌드 삭제 (25일 설정)
2. 소스코드 관리 탭
빌드 시작전 git에서 master 브랜치를 가져와서 workpace에 세팅하는 작업
3. 빌드 유발
Build when a change is pushed to GitLab. GitLab webhook URL : 체크
없을시 GitLab Plugin 과 git plugin 설치 후 gitLab에 있는 webHook 기능으로 빌드 유발
** 빌드 유발 쪽 체크
4. 빌드 환경
Delete workspace before build start + ant style **/chromeBuilding/ 을 통하여
workspace/chromeBuilding 폴더 빌드 전 삭제
이제 5번 빌드 입니다.
Build Job 은 현재 3가지가 있습니다. (포스팅할때는 이미 다 해놓은 상태에서 포스팅!)
IE Automation
Chrome Automation
FireFox Automation
세가지에 대한 빌드는 각각 다르게 돌아가지만 다 같은 내용이기 때문에 한번 포스팅 하겟습니다.
5. 빌드
빌드는 2가지로 나뉩니다.
5.1 Selenium-WebDriver

5-2 TestLink

5.1 Selenium-WebDriver
우선 셀레니엄 웹 드라이버 코드를 빌드는 매우 단순합니다.
Build 탭 - Add build step - Execute Windows batch command

을 누르신 후에 Command 에 node _auto.js [param]
_auto.js 는 미리 작성된 셀레니엄 자동화 테스트 코드 입니다.
** 테스트 타겟인 자동화 메인 페이지의 경우 (lib가 변동되거나 할때 git으로 push 또는 merge시 같은 webhook 발생)
5-2 TestLink
자 문제의 testLink 입니다.
시작하기에 앞서 중요한 점이 있습니다. testLink 버전에 따라 이슈가 있을수 있기 때문에 버전 명을 기입하겠습니다.
testLink 1.9.16(Moka pot) 버전을 사용하고 있습니다.
Jenkins 2.141
빌드 작업 전에 설치 및 세팅 작업을 해주어야 합니다.
플러그인 설치
- Jenkins Home ( Jenkins 관리 ) -> 플러그인 관리

- 필터 : TestLink 입력 후 설치 버튼

- 재 시작 후 TestLink Plugin 설치 확인 을 위해 - Jenkins 관리 - 시스템 설정

TestLink 있는지 확인
TestLInk 접속 후 (로그인까지 완료 한 상태) 아래의 아이콘을 선택하여서 API 키 생성

TestLink Installation 에서 추가 버튼 클릭 후 아래 공란 입력
Name : ( 어떤 테스트링크에 연결할지 작성 )
URL : 테스트링크주소:포트/testlink/lib/api/xmlrpc/v1/xmlrpc.php (API 사용 주소)
만약에 잘안된다면 api 주소를 찾아봐야합니다.
Developer Key 저 위에 있는 API 인터페이스 밑 개인 API 접근 키 입력

(동작 확인)

이제 빌드 단계로 가기전에 미리 해주어야 하는 작업이 있습니다.
// 테스트링크 작업 Custom Field
//
이제 다시 빌드 단계로 가면
기존에 selenium 드라이버를 실행시키는 Command 가 있습니다. 이부분에서
Add build step ! 클릭

Invoke TestLink 클릭

화면에 나타나는 TestLink Configuration 을 작성합니다.
Invoke TestLink - TestLink Configuration

TestLink Version - TestLink Installation 에서 작성한 name을 콤보 박스에서 선택
Test Project Name - TestLink 에 있는 프로젝트 이름 (아래 그림 참조)

Test Plan Name - TestLink 에서 해당 프로젝트에 따른 테스트 계획을 만들고 해당 계획을 작성합니다.
// 테스트 링크 기본 사용법은 간단하기 때문에 따로 작성하지 않겠습니다.
Build Name - 새로운 빌드시 지정될 빌드 명을 입력합니다.
AUTOMATION_$BUILD_ID 로 되어있는데 아래 그림과같이 해당 형태로 빌드 가 자동으로 생성됩니다.

Custom Fields - 매우 중요합니다. 테스트 결과에 대한 리포팅 파일에서 해당 CustomFields를 통하여서 작업 하기 때문입니다.
// TestLink 에서 커스텀 필드를 만든 후에 해당 필드 내에 값을 test Case와 일치 시킵니다.
// Test Case의 경우 한번에 넣는 방법이 있는데 이에 관련해서는 이 포스팅 다음에 번외로 작성하겠습니다.
Invoke TestLink - TestExecution
해당란에는 2가지가 있습니다.
1. Single Build Steps
해당 빌드 작업을 한번만 실행합니다.
2. Iterative Test Build Steps
해당 빌드 작업을 여러번 실행합니다.
이해가 편하게 testlink 에서 케이스가 날라옵니다. 아래의 케이스
id : 55123
name : TOP_WIDGET_CREATE
summary : 위젯이 생성되는지 테스트합니다.
caseBind(custom설정을하였다면) : TOP_WIDGET_CREATE
....
위의 한개의 케이스가 100개 1000개 있을텐데 해당 케이스가 한번에 날라오게 됩니다.
Single Build Steps의 경우는 이미 전의 테스트가 완료된 결과가 있는데 Junit이나 testNG등 리포팅 형태가 아닐 경우
해당 결과물들을 testLink Plugin 이 찾아서 실행할수 있도록 만들어 주는 커맨드를 작성합니다.
Interative Test Build Steps의 경우는 테스트 케이스가 위에 설정한 Test Plan 에 있는 순서대로 날아옵니다.
날아오는 케이스에 대한 정보를 통해서 테스트를 실행하여 결과를 받아서 사용합니다.
플러그인 도움말을 눌러 보시면 알겠지만 해당 값들을 통해서 원하는 스크립트에 파라미터로 넘길수 있습니다.
** 주의사항 (Windows는 앞뒤로 % 가 들어가야 하며 Linux 계열은 앞에 $ 가 붙어야 합니다.
Windows - %TESTLINK_TESTCASE_ID%
Linux - $TESTLINK_TESTCASE_ID

저는 첫 Build 시 node _auto.js chrome에서 결과 리포팅 파일을 만드는 작업을 하기 때문에 Test Exceution 을 사용하지 않겠습니다.
(테스트는 셀레니엄이 자체적으로 하였고 이에대한 테스트결과를 받아서 리포팅까지 작성해 놓은 상태 - 번외편에 작성하겠습니다.)
Invoke TestLink - Result Seeking Strategy
테스트 결과를 찾아서 입력 하는 과정입니다.
어떤 형태의 결과를 찾아서 입력할지 여러 방법이 있는데요 이중에서 저는 Junit Class Name 을 선택하였습니다.

입력 결과

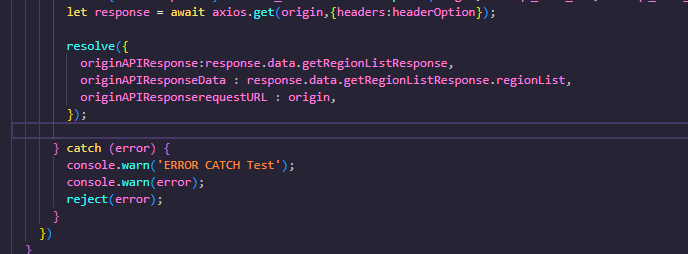
// 셀레니엄 빌드 스텝에서 ChromeBuilding이라는 디렉토리를 만들고 해당 안에 테스트케이스에 대한 결과 값들을 저장합니다.
위의 패턴은 Ant Style pattern 이며 더 찾아서 공부해보셔도 됩니다.
설명하자면 workspace/ChromeBuilding/ 폴더 안에 junit-*.xml 형태의 파일들을 읽는데 junit class name 이기 때문에
caseBind (Custom Field)의 값이 classname으로 지정되어있는 xml들을 찾아서 결과를 입력 합니다.
해당 junit리포팅 형태는
***** Pass Test Case
<testsuite>
<testcase classname="casebind" name="testName"></testcase>
</testsuite>
***** Fail Test Case
<testsuite>
<testcase classname="casebind" name="testName">
<failure type="test">Error Message</failure>
</testcase>
</testsuite>
해당형태를 지닙니다.
빌드 후 조치 단계에서는
빌드 환경에서
Delete workspace before build starts 로 해당 junit폴더를 지우고 시작했었는데요 이작업을 빌드 후 조치에서 하셔도 됩니다.
자 이제 빌드 시작 !

정상적으로 빌드가 나왔네요
눌러서 확인해보겠습니다.

45건만 자동으로 해보았는데요
첫 시작 부분은 이렇고 맨 마지막 부분은 실패한 케이스가 보이네요

일단 왜 실패했는지도 궁금하지만? 그전에 testLink 에연동이 먼저 됐는지도 봐야겠습니다.
저기 위에 결과 보면
build name : AUTOMATION_12 라고 되어있으니 testLink 에 가서확인해보겠습니다.

정상적으로 되어있는것 같습니다. 하지만 실패 케이스의 이유가 너무 궁금하기 때문에 이것을 위해서 빌드 작업에
제가 체크한 게있는데요

저부분 때문에 testLink 에서 실패 케이스로 가서 누르시면

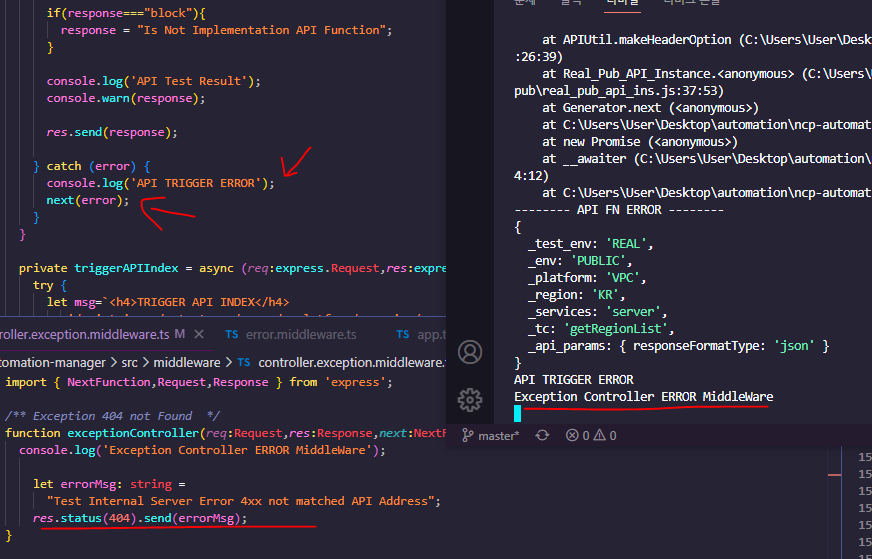
노트 부분에 결과에 대한 xml파일이 들어가 있습니다 . !!! 이부분은 제가
junit파일 생성시에
testResultArray.reduce((acc,curr,index,arr) =>{
let junitObj = {
'testsuite': {
'testcase':{
'@classname':curr.tc,
'@name':curr.tc,
}
}
};
// fail Case
if(curr.result.toLowerCase()==='fail'){
let failObj = {
'#text':curr.msg,
'@type':'failCase'
};
junitObj.testsuite.testcase['failure'] = failObj
}
// xml Create
const junit = builder.create(junitObj,{encoding:'utf-8'});
// Create xml pretty change
const xmlContent = junit.end({pretty:true});
if(curr.tc.length>=1){
makeJunitReportFile(xmlContent,dirPath,curr.tc);
}
},0);
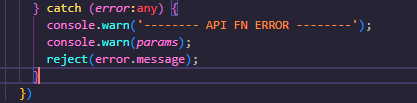
fail case일 경우에 실패 메시지와 같이 넣어 주었는데요
해당 xml을 눌러주게되면?

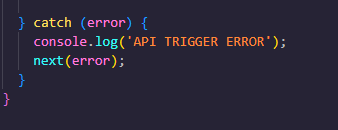
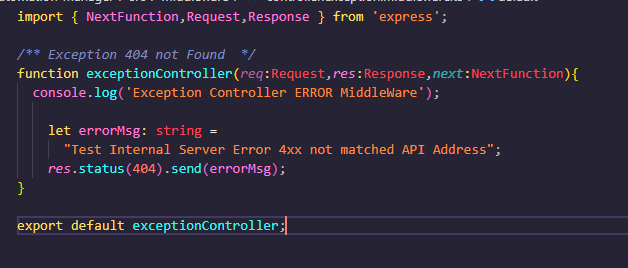
실패한 내용 (try catch 로 엮었던 직접 작성하였던) 확인이 가능합니다.!!
자동화 플로우가 다 끝났습니다.
Chrome과 FireFox는 거의 비슷하여서 문제가 없지만 ie의 경우는 문제가 많아서.. 트러블 슈팅 가이드를 따로 작성해야 할듯 합니다.
다음 포스팅은 Jenkins TestLink Intergration 마지막 작업으로
번외
1. TestCase를 한번에 넣는 방법
2. 테스트가 어떤식으로 제작되었고 젠킨스 빌드 과정 중 결과를 어떻게 받아서 처리 하였는지
로 작성하겠습니다.
1번과 2는 사실 나눈건 아니고 하나로 보시면 됩니다.
긴글 읽어주셔서 감사합니다.
꾸벅